


Команда SaaS-стартапа из 12 человек умудрилась пометить 47 из 62 задач в бэклоге как «срочные и важные». К концу двухнедельного спринта разработчики закрыли всего 11 из них. Остальные 36 автоматически перекочевали в следующий спринт ровно с теми же «горящими» метками. Ситуация абсурдная, но в ИТ-менеджменте стандартная. Когда важно всё, не важно ничего.
Кратко о главном (TL;DR)
- Матрица Эйзенхауэра — рабочий инструмент для личного планирования, но в продуктовых командах от 10 человек она не ранжирует задачи внутри квадрантов и не учитывает зависимости.
- RICE переводит приоритеты в числа и убирает субъективные споры — подходит для бэклогов от 20–30 задач.
- MoSCoW фиксирует осознанный отказ от задач на текущий период и защищает команду от раздувания бэклога.
- ABC-анализ спасает операционные команды с высоким потоком однотипных заявок — помогает отделить критические инциденты от рутины.
- Value vs Effort — самый быстрый способ визуализировать приоритеты без формул, за 15–20 минут командной сессии.
- ICE — упрощённая версия RICE для ранних стадий, когда данных мало и нужно принять решение быстро.
В продуктовых командах матрицу Эйзенхауэра в чистом виде всё реже применяют как единственный инструмент приоритизации. Рядом с ней появляются RICE, MoSCoW, ICE или ABC-анализ. Причина не в том, что матрица плоха. Её просто используют не по назначению.
Матрица Эйзенхауэра отлично работает как фильтр первого уровня и инструмент личного тайм-менеджмента. Для управления продуктом, кросс-функциональных команд и разработки она слишком грубая. Метод игнорирует критические для бизнеса параметры: стоимость задержки релиза (Cost of Delay), технические зависимости между задачами, когнитивную нагрузку на инженеров и пропускную способность системы. Когда над проектом работают от 15 человек, а входящий поток задач бесконтрольно сыплется из трёх-четырёх мессенджеров, деление на «срочно» и «важно» перестаёт давать ответ на главный вопрос: с чего конкретно начать прямо сейчас.
Теорию и базовую механику метода мы уже разбирали в статье «Матрица Эйзенхауэра для умного планирования задач», поэтому повторяться смысла нет.
В этом руководстве — пять альтернативных инструментов приоритизации, которые закрывают слепые зоны классической матрицы. Рабочая логика, формулы расчёта, продуктовые кейсы, а также ограничения и скрытые минусы каждого метода.
Почему четыре квадранта перестают работать в реальных командах

Матрица Эйзенхауэра создавалась для одного человека, который управляет собственным временем. Это важный контекст. Дуайт Эйзенхауэр управлял собственным расписанием, а не продуктовым бэклогом из 60 задач с зависимостями и SLA.
Для личных дел и быстрого первичного фильтра матрица по-прежнему работает хорошо. Потратить 10 минут на распределение списка по квадрантам ради планов на день — вполне рабочая схема.
Проблемы начинаются в четырёх конкретных ситуациях.
В команде всё «важное и срочное» одновременно. Когда продакт-менеджер смотрит на бэклог из 40 задач и честно отвечает на вопрос «это важно?» — большинство задач попадают в квадрант A. Матрица не помогает выбирать внутри квадранта. Инструмент делит задачи на группы, но не даёт порядка внутри каждого блока.
Задачи зависят друг от друга. Матрица не видит зависимостей. Задача B может быть «несрочной», но без неё задача A не может стартовать. Приоритизация по квадрантам этого не учитывает.
Нет числовой оценки ценности. «Важно» — субъективная категория. Когда руководитель разработки и продакт-менеджер спорят о приоритете двух фич, матрица не даёт аргументов. Она не переводит ценность в цифры.
Когнитивная нагрузка и переключения. Матрица упускает ограничения по количеству параллельных задач. Одновременный запуск десяти задач из квадранта A перегружает команду постоянными переключениями, что затягивает сдачу каждой из них.
Матрица Эйзенхауэра ставит не тот вопрос. Она ищет дела для первой очереди — продуктовым командам важнее считать убытки от переноса сроков. Разница в постановке вопроса полностью меняет итоговый фокус.
Метод RICE: перевод приоритетов в цифры
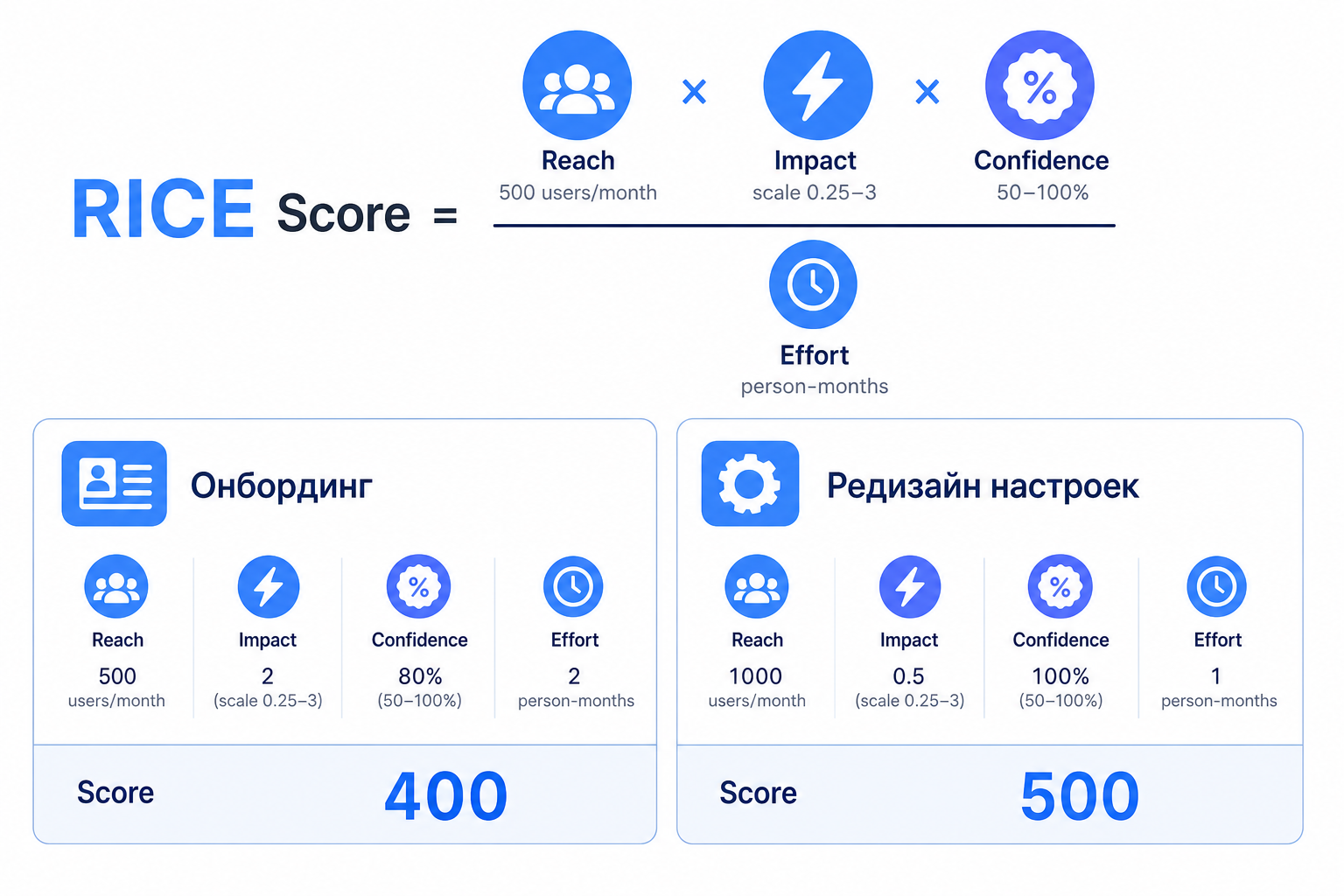

RICE — метод, который придумали в Intercom для приоритизации продуктового бэклога. Каждая задача получает числовой балл по формуле:
Score = (Reach × Impact × Confidence) / Effort
Reach — сколько пользователей или клиентов затронет задача за определённый период. Impact — насколько сильно она повлияет на каждого из них (шкала от 0,25 до 3). Confidence — насколько команда уверена в своих оценках (от 50% до 100%). Effort — сколько времени потребует реализация в человеко-месяцах или условных единицах.
Разберём на условном примере. Допустим, B2B SaaS-команда из 8 человек применяет RICE к бэклогу из 34 задач. Две задачи вызывают больше всего споров: новый онбординг для пользователей и редизайн настроек профиля.
Онбординг: Reach = 500 пользователей в месяц, Impact = 2 (высокий), Confidence = 80%, Effort = 2 месяца. Score = (500 × 2 × 0,8) / 2 = 400.
Редизайн настроек: Reach = 1000 пользователей, Impact = 0,5 (низкий), Confidence = 100%, Effort = 1 месяц. Score = (1000 × 0,5 × 1) / 1 = 500.
Цифры остужают эмоции. Интуитивно все ставили на онбординг, но за счёт двойного охвата и быстрой разработки победил редизайн. Фокус дискуссии сместился с субъективного «я считаю» на конструктивное: «Давайте пересмотрим оценку Impact для первой задачи — может, она выше 2?».
Именно в этом главная ценность RICE: он превращает спор «что важнее» в разговор о конкретных оценках и допущениях. Первые две сессии с RICE обычно занимают по два часа — команда калибрует шкалы. Потом приоритизация бэклога из 30 задач укладывается в 30–40 минут.
RICE хорошо работает при бэклоге от 20–30 задач, в продуктовых и маркетинговых командах, где важно объяснить стейкхолдерам логику выбора. Ограничение одно, но существенное: оценка Confidence субъективна. Если команда не калибрует шкалы между собой, один человек ставит 80% там, где другой поставит 50% — и результаты теряют смысл. RICE требует договорённостей, а не просто формулы.
ICE: когда нужна скорость, а не точность
ICE — упрощённая версия RICE для ситуаций, когда данных мало и решение нужно принять быстро. Формула:
Score = Impact × Confidence × Ease
Здесь нет Reach — метод не учитывает охват аудитории. Вместо Effort используется Ease (лёгкость реализации), что смещает акцент с трудозатрат на простоту исполнения. Каждый параметр оценивается по шкале от 1 до 10.
ICE хорошо подходит для стартапов на ранних стадиях, когда нет накопленной статистики по охвату, и для быстрых ретроспективных сессий. Главное ограничение: без Reach метод может вытолкнуть наверх задачи с высокой лёгкостью реализации, но низким влиянием на бизнес. Поэтому ICE часто используют как временный инструмент — до момента, когда команда накопит достаточно данных для перехода на RICE.
Подробное сравнение ICE и RICE с примерами расчётов — в материале Яндекс Практикума.
Метод MoSCoW: сила осознанного «нет»

А что, если главная проблема бэклога — не порядок задач, а то, что команда не умеет от них отказываться?
Фреймворк MoSCoW делит весь пул задач на четыре категории: обязательные (Must have), желательные (Should have), возможные при наличии ресурсов (Could have) и сознательно отклонённые на текущий период (Won't have). Этот подход официально зафиксирован в руководстве Agile Business Consortium как часть методологии DSDM.
Главное отличие от матрицы Эйзенхауэра
Суть MoSCoW — в категории Won't. В отличие от классической матрицы, которая предлагает просто «удалить» или «делегировать» неважные дела, MoSCoW вводит механизм публичного и осознанного отказа.
Категория Won't — это не размытое «сделаем когда-нибудь» и не перекладывание ответственности. Это официальная договорённость: эти задачи не трогаем в текущем релизе. Такой подход защищает команду от раздувания бэклога и избавляет от бесконечных споров посреди спринта.
Как это работает на практике
Представьте планирование квартального релиза, где на повестке стоят 40 задач. Всего за одну двухчасовую сессию команда распределяет их по категориям. 10 критически важных задач, без которых продукт не выйдет, уходят в Must. 12 ценных фич получают статус Should. Приятные бонусы, которые сделают при наличии свободного времени, попадают в Could — таких набирается 8. Оставшиеся 10 задач открыто откладывают на следующий квартал в категорию Won't.
Сортировка верхнеуровневая, зато быстрая. И все участники получают единое прозрачное понимание целей.
В чём слабость метода
MoSCoW хорошо работает на макроуровне, но пасует перед микроприоритизацией. Когда у вас на руках оказываются те самые 10 обязательных задач из категории Must, метод не подскажет, за какую браться первой. Для ранжирования внутри одной группы MoSCoW не приспособлен, поэтому его обычно комбинируют с RICE или матрицей Value vs Effort.
ABC-анализ: принцип Парето для тех, кто тонет в операционке


«У нас горит вообще всё» — эту фразу руководители служб поддержки произносят так часто, что она давно стала мемом. ABC-анализ существует ровно для того, чтобы доказать: горит далеко не всё.
ABC-анализ является прямым приложением принципа Парето к управлению задачами. Задачи жёстко делятся по их влиянию на конечный результат. Категория A — малая доля критически важных задач, приносящих основную часть результата. Категория B — задачи со средней отдачей. Категория C — большинство задач, которые в сумме почти не влияют на результат, но создают иллюзию бурной деятельности.
В классическом учёте говорят о соотношении 20/80, но на практике пропорции плавают в зависимости от отрасли и типа задач. Точные цифры вторичны — важен сам факт: ресурсы всегда распределяются неравномерно.
Кому и зачем это нужно
Этот подход спасает операционные и сервисные команды, которые ежедневно сталкиваются с огромным потоком однотипных заявок. Руководитель службы поддержки, получающий по 50 обращений в день, без чёткого фильтра неизбежно утонет в рутине, растратив до 80% времени на задачи, которые ни на что не влияют. ABC-анализ заставляет отделить критические инциденты, напрямую бьющие по клиентам, от плановых запросов и информационных писем.
Что делать, если «горит» вообще всё
При внедрении метода руководители чаще всего сталкиваются со страхом, что абсолютно все задачи срочные. Разрушить эту иллюзию помогает простой алгоритм оценки последствий.
Соберите весь поток задач за прошлую неделю и честно ответьте: что произойдёт, если конкретная задача не будет выполнена в течение суток? Потеря крупного клиента, штраф, полная остановка бизнес-процесса — категория A. Временное неудобство, задержка внутреннего отчёта, косметический дефект — категория B или C.
Когда все риски зафиксированы, мнимая срочность испаряется. Реальный критический список обычно сжимается до 10–20% от общего объёма.
Главное ограничение метода
ABC-анализ совершенно не видит зависимостей между задачами и не просчитывает стоимость задержки. Иногда мелкая рутина из категории C блокирует запуск масштабного проекта из категории A. В таких ситуациях руководителю всё равно придётся включать ручное управление и пересматривать приоритеты вопреки логике алгоритма.
Value vs Effort — самый быстрый способ визуализировать приоритеты
Это инструмент визуализации, где задачи распределяются по двум осям: ценность для бизнеса/пользователя (ось Y) и усилия на реализацию (ось X).
В результате получаются четыре квадранта. Высокая ценность при малых усилиях — Quick Wins, делаем в первую очередь. Высокая ценность при больших усилиях — стратегические задачи, которые требуют тщательного планирования. Низкая ценность при малых усилиях — второстепенные задачи по остаточному принципу. Низкая ценность при больших усилиях — «пожиратели времени», которые вычёркиваем.
Подробный разбор метода — в нашей статье «Ценность против усилий: как методика Value vs Effort помогает приоритизировать задачи».
Скорость вместо формул
В отличие от RICE, здесь не нужно высчитывать индексы. Всё, что понадобится — маркерная доска (физическая или в Miro), стикеры и 15–20 минут командного обсуждения.
Команда из 5–7 человек способна за одну сессию раскидать по матрице 20–30 задач и получить наглядную карту приоритетов. Это подходит для ранних стадий проекта, когда точных данных ещё мало, а действовать нужно быстро.
Субъективность как главное ограничение

Без жёсткой привязки к метрикам понятие «ценность» у каждого своё, что часто приводит к спорам внутри команды.
Совет для зрелых команд: если нужна воспроизводимость результатов — добавьте к Value vs Effort числовые критерии оценки ценности (например, влияние на конверсию или NPS). Вы получите скорость метода при объективности, близкой к RICE.
Как выбрать метод под свою ситуацию
Ни один из пяти методов не универсален. Вместо повторения рекомендаций — дерево решений, которое поможет выбрать метод за минуту.
Шаг 1. Сколько задач в бэклоге?
Меньше 10 → матрица Эйзенхауэра или Value vs Effort. Больше 20 → переходите к шагу 2.
Шаг 2. Есть ли у команды данные по охвату и метрикам?
Да → RICE. Нет, но решение нужно сегодня → ICE.
Шаг 3. Нужно ли зафиксировать отказ от задач перед стейкхолдерами?
Да → MoSCoW на уровне квартала или релиза.
Шаг 4. Поток задач высокий и однотипный (поддержка, операционка)?
Да → ABC-анализ для ежедневной фильтрации.
На практике команды редко используют один метод. Типичная связка: MoSCoW на квартальном планировании → RICE для ранжирования Must-задач внутри спринта → Value vs Effort для быстрых решений в середине итерации.
Отдельный момент, о котором забывают: при смене PM-инструмента накопленные данные по приоритетам (оценки RICE, категории MoSCoW, история ABC-классификации) не должны теряться. Миграция данных между системами — тема для отдельного разговора, но держите её в голове при выборе инструмента.
Если хотите попробовать эти подходы без Excel и стикеров — в Shtab можно настроить приоритеты задач, теги по методам и шаблоны повторяющихся процессов, чтобы не калибровать шкалы с нуля каждый спринт. Команды, которые внедряют формализованную приоритизацию, в среднем сокращают время на планирование спринта на 30–40% уже ко второму-третьему циклу. Подробнее о выборе инструментов — в материале «Приложения для планирования в 2026 году».
Часто задаваемые вопросы
Как внедрить RICE в команде, которая никогда не приоритизировала формально?
Начните с калибровочной сессии: возьмите 5–7 задач из текущего бэклога и оцените их всей командой. Цель первой сессии — не получить идеальные баллы, а договориться о шкалах. Что значит Impact = 3? Сколько пользователей — это «высокий Reach»? Зафиксируйте эти договорённости в документе и используйте как эталон. Обычно после двух-трёх таких сессий команда начинает оценивать задачи за 30–40 минут.
Какой метод приоритизации подходит для владельца малого бизнеса?
Для малого бизнеса с небольшой командой и смешанным потоком задач (операционка + развитие) хорошо работает связка: ABC-анализ для ежедневной операционки и Value vs Effort для стратегических задач на квартал. Оба метода не требуют специальной подготовки и занимают минимум времени на внедрение.
Какие инструменты применяются для приоритизации причин в анализе проблем?
Для приоритизации причин (например, в анализе дефектов или инцидентов) чаще всего используют ABC-анализ в связке с диаграммой Парето — она визуализирует, какие причины дают 80% негативного эффекта. В продуктовом контексте для тех же целей применяют метод «5 почему» и FMEA (анализ видов и последствий отказов).
Что делать, если команда саботирует формализованную приоритизацию?
Частая причина — ощущение, что метод отнимает время, а не экономит его. Попробуйте начать с Value vs Effort: 15 минут, стикеры, никаких формул. Когда команда увидит, что результат сессии реально влияет на план спринта (а не игнорируется руководством), сопротивление обычно снижается. Переход на RICE или MoSCoW имеет смысл только после того, как привычка приоритизировать задачи вместе уже сформировалась.