
В 2020 году исследователи проверили, какие характеристики дистанционных курсов действительно важны студентам. Результат удивил: большинство функций, которые авторы считали ценными, оказались «безразличными» — пользователям было всё равно, есть они или нет. Только одна характеристика показала линейную зависимость с удовлетворённостью. Команда, которая вложила бы ресурсы в остальные, потратила бы месяцы впустую.
Типичная картина — бэклог на 200 идей, три стейкхолдера тянут в разные стороны, ресурсов хватит на десяток фич за квартал. Скоринг помогает, но не до конца. RICE и ICE отвечают на вопрос «что важнее», а модель Кано — на другой: «как эта фича повлияет на эмоцию пользователя». Разница принципиальная. Фича с высоким RICE-скором может оказаться «безразличной» по Кано — и тогда вы потратите два спринта на то, что никто не заметит.
В этой статье — логика модели, пять категорий с примерами из российских продуктов, пошаговое проведение исследования с формулами расчёта, калифорнийская адаптация для быстрых команд и способ совместить Кано со скорингом так, чтобы бэклог перестал быть свалкой желаний.
Почему бэклог без приоритизации — это иллюзия продуктивности
Команда генерирует 50–100 идей за квартал. Реализовать может 10–15. Без системы приоритизации побеждает не лучшая идея, а самый громкий голос в комнате. У этого явления есть название — HiPPO-эффект (Highest Paid Person's Opinion). Директор сказал «нам нужен чат-бот» — и вот уже два разработчика пилят чат-бот, который никто из пользователей не просил.
Ещё хуже — стратегия «давайте сделаем всё». Представьте ресторан с меню на 200 блюд. Вы доверяете его кухне? Фокусированное меню на 20 позиций вызывает больше доверия, потому что за ним стоит осознанный выбор. С продуктом — та же история.
Скоринговые модели — RICE, ICE, MoSCoW — решают часть проблемы. Они помогают сравнить идеи по охвату, влиянию, усилиям. Но у них есть слепое пятно: они предполагают, что связь между наличием фичи и удовлетворённостью пользователя линейна. Больше фич — больше счастья.
Это не так. В том самом исследовании образовательных услуг линейную зависимость показала лишь одна характеристика из множества. Команда, которая вложила бы ресурсы в остальные, получила бы ноль прироста удовлетворённости. Именно это слепое пятно закрывает модель Кано.
Откуда взялась идея, что больше фич ≠ лучше
“Не все характеристики продукта одинаково влияют на удовлетворённость. Есть фичи, отсутствие которых бесит, но наличие воспринимается как данность — никакого «вау».
Нориаки Кано, Профессор Токийского университета, автор модели · Двухфакторная модель качества, 1984
В 1984 году профессор Токийского университета Нориаки Кано взял двухфакторную теорию мотивации Герцберга — ту самую, где есть «гигиенические факторы» и «мотиваторы» — и применил её к характеристикам продуктов.
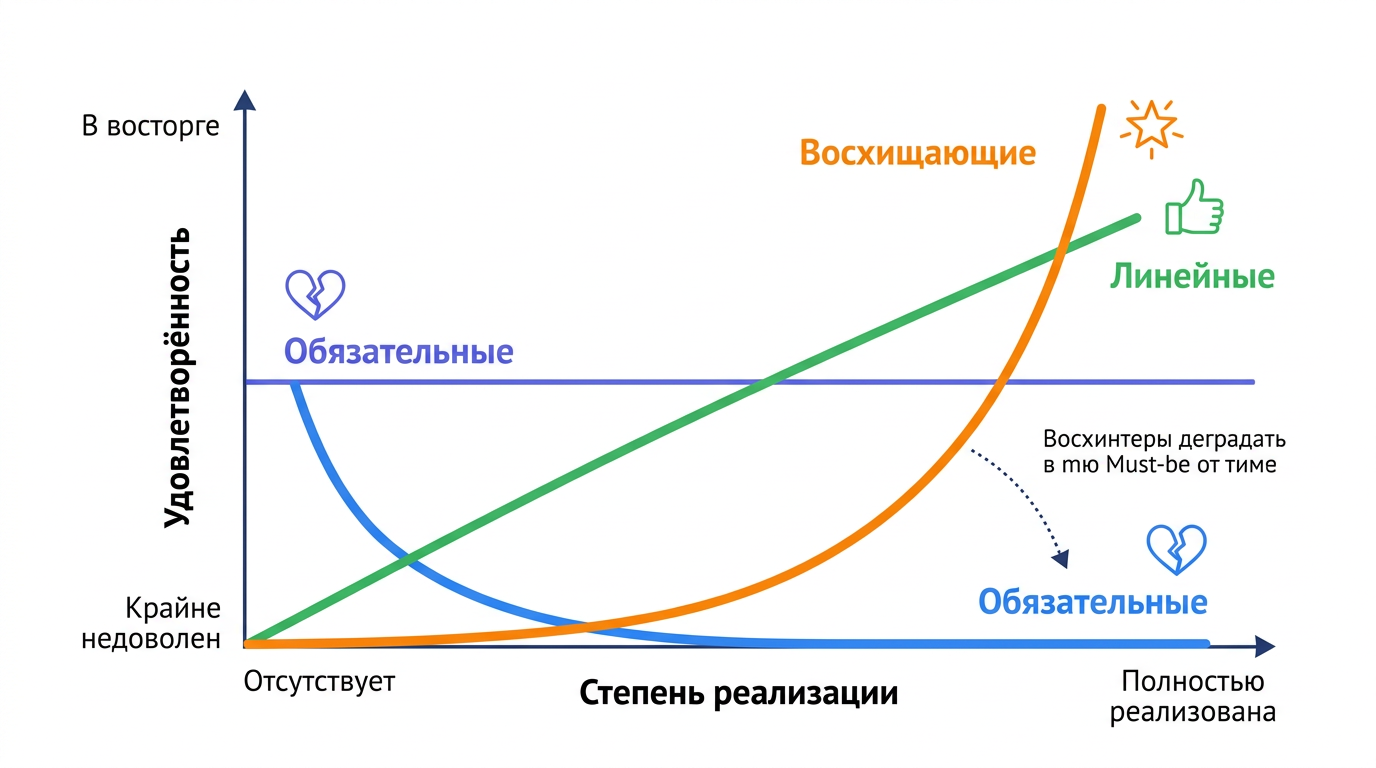
Инсайт оказался простым и неочевидным одновременно: не все характеристики продукта одинаково влияют на удовлетворённость. Есть фичи, отсутствие которых бесит, но наличие воспринимается как данность — никакого «вау». Есть фичи, которые вызывают восторг, хотя их никто не просил. И есть фичи с честной линейной зависимостью: чем лучше реализовано, тем довольнее пользователь.
Модель строится на двух осях. Горизонтальная — степень реализации функции, от «полностью отсутствует» до «полностью реализована». Вертикальная — удовлетворённость пользователя, от «крайне недоволен» до «в восторге». Каждая категория характеристик рисует на этом графике свою кривую — и кривые радикально отличаются друг от друга.
Точность предсказания потребительского поведения по модели — более 83%. Для метода, который основан на анкете из двух вопросов на каждую фичу, результат впечатляющий.
Пять категорий Кано — и почему «привлекательное» важнее, чем кажется
Как классифицировать фичу по модели Кано
Каждая категория описывает принципиально разный тип связи между функцией и эмоцией пользователя. Ошибка в классификации — это ошибка в приоритетах.
Базовое качество (Must-be) — то, что не прощают
Три ключевые категории Кано: реакция пользователя
Попробуйте мысленный эксперимент. Вы заселяетесь в отель, открываете ноутбук — Wi-Fi нет. Оставите восторженный отзыв «в этом отеле есть кровать и стены»? Вряд ли. Но отсутствие Wi-Fi — это шквал единиц на Booking.
Must-be работает именно так: есть функция — ноль эмоций, нет функции — ярость. Реакция асимметрична.
Когда компания «Скороход» запустила мобильное приложение, пользователи немедленно начали писать негативные отзывы. Одна из ключевых претензий — неудобный поиск. Умный поиск по каталогу обуви — это must-be. Никто не скажет «вау, здесь можно искать товары!». Но без нормального поиска приложением просто не будут пользоваться. Это ловушка для команд, которые пытаются «удивить» пользователей, не закрыв базу.
Одномерное качество (Performance) — рабочая лошадка продукта
Здесь всё интуитивно: больше — лучше, быстрее — лучше, удобнее — лучше. Связь между реализацией и удовлетворённостью — прямая линия.
Сервис «Сплит» от Яндекс.Маркета — классический performance-фактор. Чем удобнее и доступнее оплата частями, тем больше покупок. Результат — рост в 1,5 раза. Не вау-эффект, а стабильный, предсказуемый рост. Именно поэтому команды часто фокусируются только на performance. Это ошибка: без must-be вы теряете пользователей, без delighters — не отличаетесь от конкурентов.
Привлекательное качество (Attractive/Delighter) — неожиданный восторг
«Надеюсь, в приложении обувного магазина можно примерить кроссовки через камеру» — так не думает ни один пользователь. Но когда виртуальная примерка обуви появилась в приложении «Скороход», ею делились, о ней рассказывали друзьям, она запоминалась.
Вот что критично: delighters деградируют со временем. Подсветка экрана в электронных ридерах когда-то вызывала восторг — покупатели не верили, что можно читать в темноте без лампы. Сегодня ридер без подсветки — дефектный продукт. Вчерашний delighter становится performance, а потом — must-be. Поэтому исследование по Кано нужно повторять регулярно, а не проводить один раз и забыть.
Безразличное и нежелательное — куда утекают ресурсы
Безразличное (Indifferent) — пользователю всё равно, есть фича или нет. Нежелательное (Reverse) — фича активно раздражает. Навязчивый онбординг, который нельзя пропустить, автоматическое воспроизведение видео на главной — кто-то в команде считал это «улучшением UX». Пользователи считают иначе.
Вернёмся к исследованию дистанционных курсов: большинство характеристик, которые авторы курсов считали ценными, попали в категорию indifferent. Три месяца разработки, торжественный релиз — а пользователи даже не замечают. Сводка реакций по всем категориям:
- Must-be: есть → нейтрально, нет → гнев
- Performance: хорошо реализовано → удовлетворён, нет → разочарован
- Attractive: есть → восторг, нет → не заметил
- Indifferent: есть → всё равно, нет → всё равно
- Reverse: есть → раздражён, нет → доволен
Как провести исследование по Кано: от анкеты до карты удовлетворённости
Модель Кано — не абстрактная схема для презентаций. Это конкретный исследовательский метод с чёткой последовательностью действий.
Шаг 1. Формулировка вопросов. Для каждой функции составляется пара: функциональный вопрос («Как вы отнесётесь, если в приложении появится возможность оплаты частями?») и дисфункциональный («Как вы отнесётесь, если такой возможности не будет?»). На каждый — пять вариантов ответа: мне это нравится, я этого ожидаю, мне всё равно, я могу с этим смириться, мне это не нравится. Формулировки — на языке пользователя, не разработчика. Не «реализация микросервиса push-нотификаций», а «уведомления о скидках на товары из вашего списка желаний».
Шаг 2. Классификация ответов. Пересечение двух ответов даёт категорию по оценочной таблице Кано — матрица 5×5. Если на функциональный вопрос человек ответил «мне это нравится», а на дисфункциональный — «мне всё равно», фича попадает в категорию Attractive. Если «я этого ожидаю» + «мне это не нравится» — Must-be.
Нюанс, который часто упускают: модель поддерживает сегментацию до 8 возрастных групп, плюс разбивку по полу и доходу. Одна и та же фича может быть delighter для студентов 20 лет и indifferent для предпринимателей 45 лет. Анализируете ответы «в среднем по больнице» — теряете самое ценное.
Шаг 3. Расчёт индексов. Две формулы, которые превращают качественные данные в количественные:
ИУП (индекс удовлетворённости) = (A + O) / (A + O + M + I)
ИНП (индекс неудовлетворённости) = -(O + M) / (A + O + M + I)
Где A — attractive, O — one-dimensional, M — must-be, I — indifferent. ИУП показывает, насколько фича способна обрадовать пользователя. ИНП — насколько её отсутствие способно расстроить. Фича с высоким ИУП и низким по модулю ИНП — delighter: наличие радует, отсутствие не огорчает. Фича с низким ИУП и высоким по модулю ИНП — must-be: наличие не радует, отсутствие бесит.
Шаг 4. Визуализация на карте. Нанесите каждую фичу точкой на двумерную карту: ИУП по вертикальной оси, ИНП по горизонтальной. Четыре квадранта сразу покажут, к какой категории тяготеет функция. Must-be скопятся в правом нижнем углу, delighters — в левом верхнем, performance — в правом верхнем. А indifferent будут жаться к началу координат — туда, где ни радости, ни горя.
Калифорнийская модель Кано — упрощение, которое работает
Классический метод требует времени. Сформулировать пары вопросов, собрать ответы, заполнить матрицу, рассчитать индексы — на всё уходит одна-две недели. Для компании с выделенным UX-исследователем это нормально. Для стартапа из пяти человек — роскошь.
Калифорнийская адаптация решает эту проблему. Вместо пары «функциональный + дисфункциональный вопрос» — один комбинированный вопрос с визуальной шкалой. Респондент оценивает одновременно важность функции и свою удовлетворённость ею. Анкета становится вдвое короче, response rate растёт, проводить можно хоть каждый спринт.
Но есть цена. Теряется нюансировка. В пограничных случаях сложнее отличить must-be от performance — а именно на границе категорий часто прячутся самые интересные инсайты. Калифорнийский Кано — экспресс-тест, а не полное обследование.
Когда его использовать: на ранних стадиях продукта, при быстрой валидации гипотез, в командах без бюджета на полноценное исследование. Команда из пяти человек справится за два-три дня: день на составление анкеты, день на рассылку и сбор, день на анализ. Классический вариант потребует неделю-две. Для команд, которые раньше не приоритизировали вообще, даже упрощённый Кано — качественный скачок по сравнению с «давайте проголосуем».
Почему Кано без скоринга — только половина ответа
После исследования по Кано у вас может быть десять delighters. Какой делать первым? Три must-be. Какой критичнее? Кано не ответит. Модель классифицирует тип влияния фичи на эмоцию, но молчит о стоимости разработки, охвате аудитории и уровне уверенности в данных.
Решение — гибридная приоритизация. Сначала Кано определяет категорию, затем внутри категории — ранжирование по RICE или ICE. Логика приоритетов: сначала must-be (убрать источники гнева), потом performance (обеспечить стабильный рост метрик), потом delighters (создать дифференциацию). Но внутри каждой группы — скоринг по затратам, рискам, охвату.
Конкретный пример. У вас три must-be фичи. Первая затрагивает 80% пользователей и стоит два спринта. Вторая — 20% пользователей и стоит пять спринтов. Третья — 60% пользователей, стоит один спринт. Кано не различит их — все три одинаково «базовые». А RICE покажет, что третья — лучший старт: максимальный охват на единицу усилий.
На практике это выглядит так: вы проводите исследование по Кано, размечаете бэклог по категориям, а дальше работаете с привычными инструментами управления проектами. В Shtab.app можно создать теги для категорий Кано — must-be, performance, delighter — и фильтровать задачи на канбан-доске по этим тегам. Это позволяет видеть распределение бэклога и быстро замечать перекосы: если 70% задач в спринте — delighters, а must-be висят нетронутыми, что-то пошло не так.
Кано отвечает на вопрос «зачем», скоринг — на вопрос «когда». Вместе они дают полную картину.
Кейс Яндекс.Маркет: как «Сплит» увеличил покупки в 1,5 раза
Яндекс.Маркет — маркетплейс с миллионами пользователей. Проблема: крупные покупки откладывались. Пользователи хотели новый смартфон или робот-пылесос, но не были готовы отдать всю сумму сразу. Добавляли товар в избранное и... забывали.
Оплата частями — сервис «Сплит» — это не delighter. Рассрочка уже стала нормой рынка, пользователи ожидали такую возможность. Это и не must-be — без рассрочки маркетплейс всё ещё работает, никто не ставит единицу в отзывах из-за её отсутствия. Чистый performance-фактор: линейная зависимость между удобством оплаты и количеством покупок.
Результат: покупки выросли в 1,5 раза, особенно в сегменте дорогих товаров (данные приводятся по вторичному источнику, не по официальной отчётности Яндекса). Не потому что пользователи были в восторге, а потому что барьер к покупке снизился пропорционально удобству сервиса. Performance работает так — без фейерверков, но с цифрами в отчёте.
В том же контексте стоит вспомнить «Скороход». Когда компания обратилась за редизайном приложения, бюджет был ограничен — нельзя было сделать всё и сразу. Классификация по Кано расставила приоритеты: сначала must-be (умный поиск, без которого пользователи писали гневные отзывы), потом performance (поиск по фото), и только потом delighters (виртуальная примерка, видеоконсультации). Тональность отзывов сменилась с негативной на позитивную. Сначала убери боль, потом добавляй радость.
Что ломает исследование по Кано
Метод работает, когда его применяют правильно. Вот что идёт не так чаще всего.
«Мы уже проводили Кано в прошлом году». Категории мигрируют. Подсветка ридера была delighter, стала must-be. Тёмная тема в приложении три года назад удивляла, сейчас её отсутствие раздражает. Пересматривайте классификацию минимум раз в полгода, а для быстрорастущих рынков — раз в квартал.
«Усреднили по всем пользователям — и хватит». «Средний пользователь» не существует. Фича, которая delighter для одного сегмента, может быть indifferent для другого. Модель позволяет сегментировать до 8 возрастных групп плюс пол и доход — используйте эту возможность, а не хороните её в усреднённых данных.
«Как вы отнесётесь к реализации асинхронного пуш-канала?» Это не вопрос для пользователя. «Как вы отнесётесь к уведомлениям о снижении цены на товары из вашего списка?» — уже лучше. Качество формулировок напрямую влияет на качество данных. Мусор на входе — мусор на выходе.
Когда Кано не нужен
Не каждая ситуация требует полноценного исследования. Если у вас в бэклоге 10 задач и все они — баги, Кано избыточен. Если продукт на стадии MVP и пользователей ещё нет — не у кого спрашивать. Если решение нужно принять за день — калифорнийский вариант поможет, но классический не успеете.
Кано максимально полезен, когда бэклог разросся, команда спорит о приоритетах, а пользователи уже есть и готовы отвечать на вопросы. Это инструмент для зрелых продуктов с реальной аудиторией, а не для проверки первых гипотез.
Ещё одно ограничение: модель показывает текущее восприятие. Она не предсказывает, как изменятся ожидания через год. Для стратегического планирования нужны другие инструменты — Jobs to Be Done, трендовый анализ, глубинные интервью. Кано — тактическое оружие для квартального и спринтового планирования.
Попробуйте прямо сейчас
Откройте бэклог. Возьмите три верхних задачи. Для каждой задайте двум-трём пользователям пару вопросов: «Как отнесётесь, если это появится?» и «Как отнесётесь, если этого не будет?». Даже без матрицы, без индексов, без формул — вы удивитесь, сколько «приоритетных» задач окажутся indifferent. А какая-нибудь фича из конца списка вдруг вызовет реакцию «без этого вообще не могу пользоваться».
Лучший бэклог — не самый длинный, а тот, где каждая задача прошла проверку реальностью.



